
Quick Links
- Which open-source/free tools should you use for Elasticsearch monitoring?
- Monitoring Elasticsearch with open-source tools
- So which tool should you choose?
- Why standard monitoring tools aren’t enough
- Conclusion
Which open-source/free tools should you use for Elasticsearch monitoring?
Published on: November 2022
Observability is a critical aspect of operating any system, exposing its inner workings, and facilitating the detection and resolution of problems. Monitoring tools serve as the first and most basic layer in system observability. In Elasticsearch, the search engine that powers so many of today’s applications, reliable monitoring is an absolute must and is the primary building block of a successful operation.
Elasticsearch infrastructure can be quite complex, requiring the monitoring of many performance parameters that are often interlinked. These include memory, CPU, cluster health, node availability, indexing rates, and JVM metrics (e.g., heap usage, pool size, and garbage collection). There are multiple open-source monitoring tools available for Elasticsearch, each with its advantages and limitations. While these tools can be extremely useful, as operations scale, it is common to encounter issues that aren’t easily resolved with the standard tools.
This blog post will explore popular open-source tools for Elasticsearch tracking, their defining features, and their key differences. It will also explain where such standard monitoring tools are lacking and how Opster can help you achieve optimal Elasticsearch performance.
Monitoring Elasticsearch with open-source tools
1. Cerebro
An open-source MIT-licensed web admin tool, Cerebro enables Elasticsearch users to monitor and manipulate indexes and nodes, while also providing an overall view of cluster health. It has over a million downloads on Docker and 30 stars on GitHub. Cerebro is similar to Kopf, an older monitoring tool that was installed as a plugin on earlier Elasticsearch versions. When web applications could no longer run as plugins on Elasticsearch, Kopf was discontinued and replaced by Cerebro, a standalone application with similar capabilities and UI.
Built with Scala, AngularJS, Framework, and Bootstrap, Cerebro can be set up easily, in just a few steps. It also boasts built-in capabilities to conveniently track and oversee operations in Elasticsearch, including resyncing corrupted shards to another node, a dashboard showing the replication process in real-time, configuring backup using snapshots, and activating a selected index with a single click.
The Cerebro community is relatively small, resulting in less frequent updates and fewer features. Its documentation is sparse and, like ElasticHQ, it doesn’t support data from logs. In addition, while it is an excellent tool for tracking real-time processes, Cerebro does not provide graphs with historic/time-based node statistics and, thus, doesn’t offer anomaly detection or troubleshooting capabilities.

2. Prometheus and Grafana
Prometheus is a powerful metric-collection system capable of scraping metrics from Elasticsearch. Grafana is a tool that, when coupled with Prometheus, can be used to visualize Elasticsearch data. Both Prometheus and Grafana have larger communities and more contributors than ElasticHQ and Cerebro and, therefore, provide more features and capabilities. Prometheus and Grafana have 28.1K stars and 32.5k stars on GitHub respectively, and both have over 10 million downloads on Docker.
Able to display data over long periods of time, Grafana features versatile visual capabilities, including flexible charts, heat maps, tables, and graphs. It also provides built-in dashboards that can display information taken from multiple data sources. There are a large number of ready-made dashboards created by the Grafana community, which can be imported and used in your environment. For example, Grafana’s Elasticsearch time-based graphs can display meaningful statistics on nodes. These capabilities make Grafana a good solution for visualizing and analyzing metrics, enabling users to add conditional rules to dashboard panels that can trigger notifications.
A major drawback of Grafana is that it doesn’t support full-text data querying. Moreover, just like ElasticHQ and Cerebro, it doesn’t support data from logs.
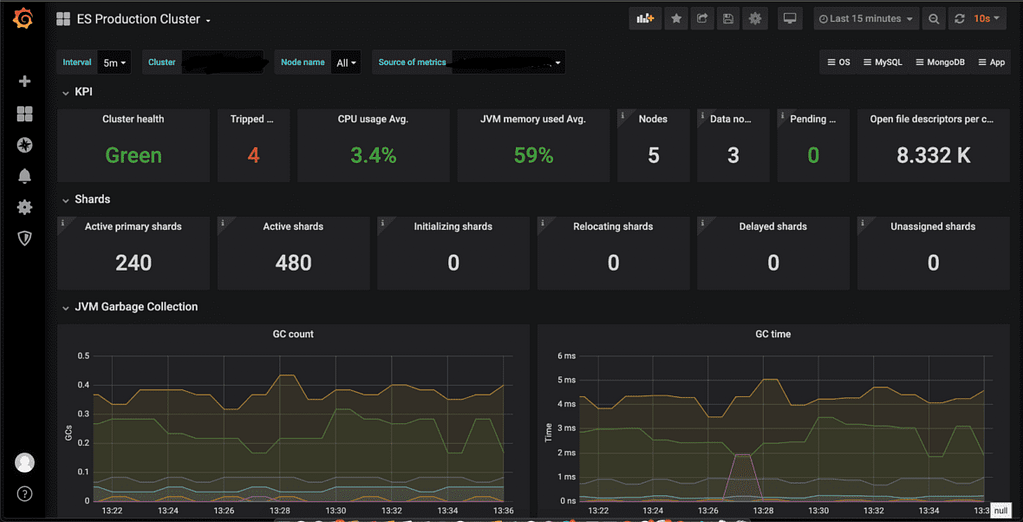
3. ElasticHQ (not maintained anymore)
ElasticHQ is an open-source application featuring a user-friendly interface to manage and monitor Elasticsearch clusters. The tool was almost single-handedly developed by Roy Russo as an impressive personal project intended to help Elasticsearch users.
ElasticHQ is available as a Python-based project on GitHub, where it received 4.3K stars, or as a Docker Image on Docker Hub, with over one million downloads. It is easy to install and its UI provides access to all the statistics exposed by Elasticsearch. It also offers both querying capabilities and a selection of pre-designed charts. This allows users to monitor clusters, nodes, indices, shards, and important cluster metrics. Furthermore, ElasticHQ grants users some degree of control over Elasticsearch operations, including the ability to maintain and reindex indices, copy mapping, perform diagnostics, and more.
Despite the many advantages ElasticHQ offers, the project had a relatively small number of contributors, leading to a slower release cycle and a lack of certain capabilities. For example, the tool doesn’t support alerts, and its charts lack flexibility. Another obvious disadvantage is that ElasticHQ doesn’t support the collection and analysis of logs, which often contain important information and warnings. However, this is not unique to ElasticHQ, as we’ll discuss in the following sections
Elastic’s license changes, frequent backwards incompatibilities, and crippling of their “open source” python libs were too much to keep up with. As a result, ElasticHQ is no longer maintained.
4. Elastic Stack
Elastic provides monitoring features that oversee the performance of the entire Elastic Stack, including Elasticsearch, Kibana, Beats, and Logstash. Like Prometheus and Grafana, Elastic also has large user and contributor communities.
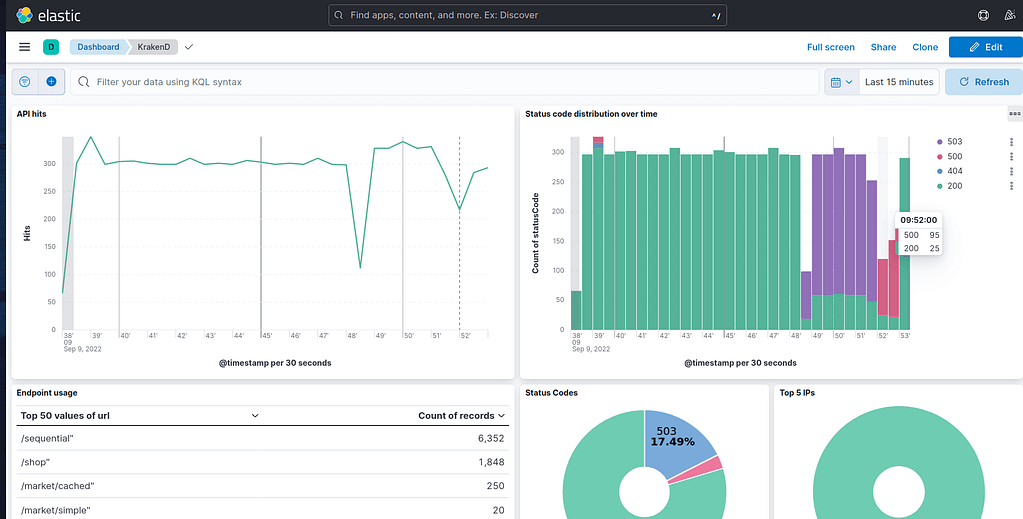
Kibana offers a collection of dashboards to help monitor and optimize the entire Elastic Stack. It can handle log data and features a rich array of dynamic visualization options that can be easily changed and filtered. These include pie charts, line charts, tables, geographical maps, and markdown visualizations, which can all be combined into dashboards. Kibana can also be used to search for a specific event within the data and can facilitate diagnostics and root-cause analysis.
One of the downsides of Kibana’s open-source version (OSS) is its lack of out-of-the-box alerting features. And though upgrading to Elastic X-Pack will provide the alerting functionality, you will still need to configure the alerts yourself.
So which tool should you choose?
Before you go straight for the Elasticsearch monitoring tool with the greatest functionality, there are a few things to consider.
First, Cerebro was specifically designed for Elasticsearch and is easy to set up and operate. Nevertheless, it has fewer its documentation is sparse, it doesn’t support data from logs, and does not provide graphs with historic/time-based node statistics.
Second, as generic monitoring tools, Prometheus and Grafana enable you to monitor everything, but they aren’t tailored to Elasticsearch specifically. This can be quite limiting. Despite that users can plot many different kinds of graphs in Grafana, they cannot display which nodes are connected to the cluster and which have been disconnected. In addition, Grafana does not support an index or shard view, making it impossible to see where shards are located or to track the progress of shard relocation.
In addition, ElasticHQ is no longer maintained but can be used at your own risk and while Elastic comes with advanced monitoring capabilities, the setup and operation are more labor-intensive and require greater expertise than the other options.
Why standard monitoring tools aren’t enough
When it comes to Elasticsearch, even with reliable monitoring tools in place, you may still encounter sudden, unexpected, and serious downtime episodes. Let’s take a closer look at why this is the case.
There are several reasons monitoring tools alone aren’t enough. For starters, it’s bad practice to install a monitoring tool and forget about it. Rather, you should keep up with the latest configuration guidelines and best practices and know how to implement them correctly.
Second, choosing which metrics to monitor and knowing how to analyze them is no small feat, as Elasticsearch infrastructure can become quite complex. With so many metrics interacting with each other, even the smallest change can adversely impact performance. A monitoring tool may indicate you’ve run out of memory, for example, but this information alone isn’t enough to identify the underlying cause, let alone to resolve the issue and prevent a recurrence.
Also, while traditional commercial monitoring tools are useful for event correlation and providing alerts, they still lack the capabilities needed to truly get to the bottom of your Elasticsearch issues. Despite claims of providing root-cause analysis, these solutions generally provide basic event correlation analysis while failing to identify the root cause, which is critical for forecasting and avoiding future issues.
Elasticsearch performance is crucial, especially as operations scale or when applications that affect end users are on the line. Successfully operating Elasticsearch requires much more than improved monitoring and alerts: Teams must have access to tools with advanced prediction and problem-solving capabilities in order to tackle the complicated issues that may arise.
Conclusion
Ensuring visibility is critical for successfully managing complex systems. While there are many tools available for monitoring Elasticsearch, not all are created equal. Most standard tools offer only basic analysis and do not get to the heart of the problem. Given the complexity of Elasticsearch, this is inadequate in production, especially for operations at scale or those affecting customer experience.