Prevent Search Latency Issues with Opster's Search Gateway
The Search Gateway provides what is desperately missing in critical ES deployments - with it, you can now block heavy searches from causing downtime and latency issues.If you’re experiencing slow searches and latency issues in Elasticsearch, or having difficulty pinpointing heavy searches, you need more than what monitoring tools can provide. With the Search Gateway you’ll get advanced search visibility and can automatically prevent unwanted heavy searches.
Get a Demo
Start blocking heavy searches
"*" indicates required fields
Trusted by Fortune 500 & Startups










A heavy search is a search that causes latency, not to be confused with a search that is slow due to existing latency in the system.
Yes, you can. The Search Gateway is configured to protect the cluster out-of-the-box, but you have the ability to configure the settings according to your specific system.
There are a number of options for allowing a specific search to run despite its size and resource utilization. You can configure the allowance according to user roles, specifications and other attributes.
No, the Search Gateway works efficiently and async with the usual latency of less than a millisecond.
The Search Gateway knows how to identify when slow searches are causing load on your cluster, versus when searches are running slowly because your cluster is loaded for other reasons.
The Search Gateway is a lightweight process that scans the requests efficiently and forwards them. Usually, 2 to 4 GB of memory with two cores will suffice, depending on the workloads.
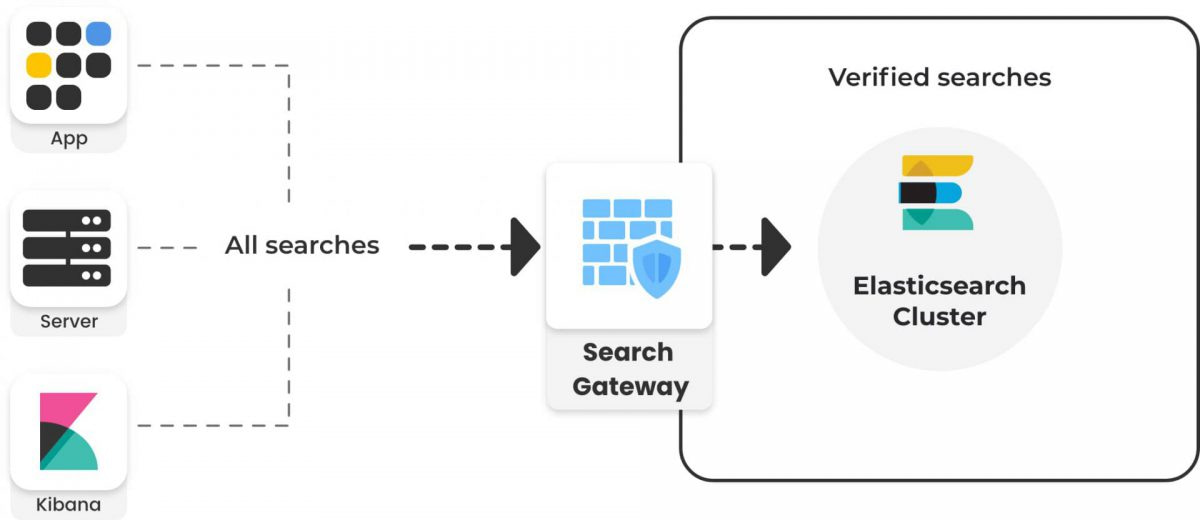
You can use the Search Gateway in multiple ways. It can be used solely for detection, but its power lies in its ability to prevent heavy searches from breaking your cluster.
No, you can think of the Search Gateway as a lightweight reverse proxy. The SG proxies the requests to the cluster, which then coordinates the search internally.
Yes, with the visibility afforded by the Search Gateway you can group stats according to user and application.
As with any mission-critical network device, it’s recommended to have more than one for high availability purposes.
The Search Gateway comes out of the box with metrics and a Grafana dashboard to allow for easy set up of alerts. The Gateway is a lightweight process that can be restarted or removed quickly when needed.
Yes. The Search Gateway begins detecting your heavy searches right away upon installation. You can always adjust settings as needed.
All versions!
Opster's Search Gateway Vs. Generic Monitoring Tools Vs. Slow Logs
What To Expect From Your DemoCall With Opster
- 1Put Out Fires - Our support engineers will answer any burning Elasticsearch questions you may have.
- 2See How Our Products Work - We’ll show you how we improve ES performance with the Search Gateway and our other products for optimization.
- 3Choose Your Product Plan - We’ll discuss your ES needs, offer you the relevant product package and provide you with a price quote.
Having worked with Opster in optimizing our environment, I can say that Opster’s knowledge of Elasticsearch is really comprehensive. In my opinion, Opster is a must-have for all companies with mission-critical Elasticsearch.

The cost of Elasticsearch downtime can be significant. Opster is what organizations need to streamline their Elasticsearch operations.

Using Opster’s ESsentials, we were able to scale our operations and channel our focus into growing our company.
