
Quick Links
- Text analysis – tokenization and normalization
- Analyzers
- Built-in analyzers
- Standard analyzer
- English stop words filter
- German stop words filter
- File-based stop words
- Custom analyzers
Overview
Elasticsearch prepares incoming textual data for efficient storing and searching. The text fields undergo an analysis process, formally called Text Analysis, where the content of text fields is broken down into individual tokens and are then enriched, transformed, synonymized, stemmed and captured in the inverted indices.
Understanding the text analysis process can help us troubleshoot search-related issues. Learning about the mechanics of analyzers and their building blocks helps us understand how to work with analyzers, as well as how to build custom analyzers for various languages (if required).
In this article, we will review the fundamentals of text analysis and analyzers (the building blocks of text analysis), and then look at the standard analyzer in depth. We will also walk through a few examples, including creating a custom analyzer.
Text analysis
The text analysis process is tasked with two functions: tokenization and normalization.
- Tokenization – a process of splitting text content into individual words by inserting a whitespace delimiter, a letter, a pattern, or other criteria. This process is carried out by a component called a tokenizer, whose sole job is to chop the content into individual words called tokens by following certain rules when breaking the content into words.
- Normalization – is a process where the tokens (words) are transformed, modified, and enriched in the form of stemming, synonyms, stop words, and other features. Stemming is an operation where the words are reduced (stemmed) to their root words: for example, “game” is a root word for “gaming”, “gamer” including the plural form “gamers”.
The text analysis is carried out by employing so-called analyzers. Both these functions, tokenization and normalization, are carried out by the analyzer module. An analyzer does this by employing one tokenizer and zero or more token filters.
Elasticsearch provides a set of prebuilt analyzers that work for most common use cases. In addition to the common standard and keyword analyzers, the most notable are: simple, stop, whitespace, pattern, language, and a few other analyzers. There are language-specific analyzers too, like English, German, Spanish, French, Hindi, and so on.
While this analysis process is highly customizable, the out-of-the-box analyzers fit the bill for most circumstances. Should we need to configure a new analyzer, we can do so by mixing and matching one tokenizer and character and token filters (the components that make an analyzer) from a given catalog of them.
Analyzers
An analyzer module consists of essentially three components – character filters, the tokenizer and token filters – as the figure below demonstrates. These three components form a pipeline that each of the text fields pass through for text processing. While both character and token filters are optional in a text analysis pipeline, the tokenizer is a mandatory component.
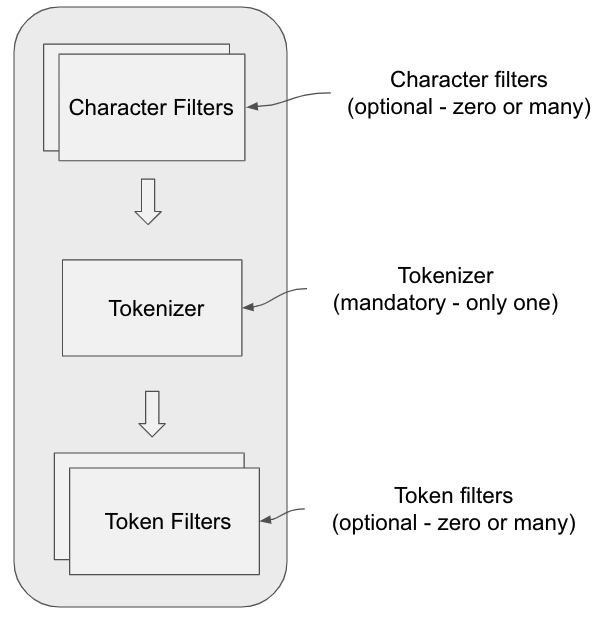
Figure 7.1 Anatomy of an analyzer module
Let’s briefly go over these components.
Character filters
The character filter’s job is to remove unwanted characters from the input text string.
Elasticsearch provides three-character filters out of the box: html_strip, mapping and pattern_replace.
These character filters are optional. For example when a text
<\h1> Opster ops is awesome <\h1>is passed through the html_strip character filter, the h1 tags will be removed. The mapping character filter helps map some text with alternative text (e.g: h2o – water, hcl – hydrochloric acid etc), while the pattern_replace fitler matches text in a regular expression (regex) and replaces it with its equivalent (e.g., match an email based on a regex and extract the domain of the organization).
Tokenizers
The tokenizers split the body of text into words by using a delimiter such as whitespace, punctuation, or some form of word boundaries. For example, if the phrase “Opster ops is AWESOME!!” is passed through a tokenizer (we consider a standard tokenizer for now), the result will be a set of tokens: “opster”, “ops”, “is”, “awesome”. The standard tokenizer will apply a set of rules based on grammar. The tokenizer is a mandatory component of the pipeline – so every analyzer must have one, and only one, tokenizer.
Elasticsearch provides a handful of these tokenizers to help split the incoming text into individual tokens. The words can then be fed through the token filters for further normalization. A standard tokenizer is used by Elasticsearch by default, which breaks the words based on grammar and punctuation. In addition to the standard tokenizer, there are a handful of off-the-shelf tokenizers: standard, keyword, N-gram, pattern, whitespace, lowercase and a handful of other tokenizers.
Token filters
Token filters work on tokens produced by the tokenizer for further processing. For example, the token can change the case, create synonyms, provide the root word (stemming), or produce n-grams and shingles, and so on. Token filters are optional. They can either be zero or many, associated with an analyzer module. There is a long list of token filters provided by Elasticsearch out-of-the-box. You can learn more about how to use token filters to improve synonym searches in Elasticsearch here.
Built-in analyzers
Elasticsearch provides over half a dozen out-of-the-box analyzers that we can use in the text analysis phase. These analyzers most likely suffice for the basic cases, but should there be a need to create a custom one, one can do that by instantiating a new analyzer module with the required components that make up that module. The table below lists the analyzers that Elasticsearch provides us with:
| Analyzer | Description |
|---|---|
| Standard analyzer | This is the default analyzer that tokenizes input text based on grammar, punctuation, and whitespace. The output tokens are lowercase and stop words are removed. |
| Simple analyzer | A simple analyzer splits input text on any non-letters such as whitespaces, dashes, numbers, etc. It lowercases the output tokens, too. |
| Stop analyzer | A variation of the simple analyzer with English stop words enabled by default. |
| Whitespace analyzer | The whitespace analyzer’s job is to tokenize input text based on whitespace delimiters. |
| Keyword analyzer | The keyword analyzer doesn’t mutate the input text. The field’s value is stored as is. |
| Language analyzer | As the name suggests, the language analyzers help work with human languages. There are dozens of language analyzers such as English, Spanish, French, Russian, Hindi and so on, to work with different languages. |
| Pattern analyzer | The pattern analyzer splits the tokens based on a regular expression (regex). By default, all the non-word characters help to split the sentence into tokens. |
| Fingerprint analyzer | The fingerprint analyzer sorts and removes the duplicate tokens to produce a single concatenated token. |
The standard analyzer is the default analyzer and is widely used during text analysis. Let’s look at the standard analyzer with an example in the next section.
Standard analyzer
The standard analyzer is the default analyzer whose job it is to tokenize sentences based on the whitespaces, punctuation, and grammar. The pipeline is made of no character filters, one standard tokenizer and two token filters: lowercase and stop words. However, the stop words token filter is disabled by default (we will look at an example of how to switch on the stop words later in the article). The figure below shows the components of a standard analyzer:

As the figure depicts, the standard analyzer consists of a standard tokenizer and two token filters: lowercase and stop token filters with no character filter. Below is an example of what happens when a text field containing the following content is processed by text analyzers:
“Opster Ops is so cool 😎 and AWESOME 👍!!!“
The text gets tokenized and the list of tokens are split as shown here in a condensed form:
[“opster”, “ops”, “is”, “so”, “cool”,”””😎”””, “and”,”awesome”,”””👍”””]
The tokens are lowercased and the exclamation marks were removed as the output shows. The emojis were saved as textual data. The above text is analyzed by a standard analyzer (default), which tokenizes the words based on a whitespace and strips off non-letter characters like punctuation.
We can test the analyzer in action using the _analyze API as demonstrated by the following code:
GET _analyze
{
"text": "Opster Ops is so cool 😎 and AWESOME 👍!!!"
}This code analyzes the given text with a standard analyzer (remember, standard analyzer is the default analyzer) and spits out the output as shown in the figure below:

The words were split based on whitespace and non-letters (punctuation), which is the output of the standard tokenizer. The tokens are then passed through the lowercase token filter.
We can add the specific analyzer during our text analysis testing phase by adding an additional analyzer attribute in the code. For example, the earlier query can be rewritten this time by specifying a specific analyzer. Here is an updated query with the explicit setting of the analyzer:
GET _analyze
{
"analyzer": "standard",
"text": "Opster Ops is so cool 😎 and AWESOME 👍!!!"
}As you can imagine, we can replace the value of the analyzer to our chosen one based on the analyzer we want to test, like: “standard” or “keyword”, for example.
Although the standard analyzer is clubbed with a stop words token filter, the stop words filter is disabled by default. We can, however, switch it on by configuring its properties, which is discussed in the next section.
English stop words filter
Elasticsearch allows us to configure a few parameters such as the stop words filter, stop words path, and maximum token length on the standard analyzer at the time of index creation. Let’s take an example of enabling English stop words on the standard analyzer.
We can do this by adding a filter during index creation:
PUT my_index_with_stopwords
{
"settings": {
"analysis": {
"analyzer": {
"standard_with_stopwords":{
"type":"standard",
"stopwords":"_english_"
}
}
}
}
}The settings block is used to set an analyzer of our choice. As we are modifying the built-in standard analyzer, we give it a unique name (standard_with_stop words is the name of the analyzer in our case) and set it with a standard type (meaning standard analyzer) with English stop words enabled (stop words is set to _english_).
Now that we’ve created the index with a standard analyzer that is configured with the stop words, any text that gets indexed goes through this modified analyzer (provided the field is pre-declared with this analyzer during the mapping phase). To test this, we can invoke the _analyze endpoint on the index as demonstrated here in the code listing:
POST my_index_with_stopwords/_analyze
{
"text": "Opster Ops is so cool 😎 and AWESOME 👍!!!",
"analyzer": "standard_with_stopwords"
}As you can see in the output of this call below, the common words such as “is” and “and” were removed by our standard_with_stop words analyzer:
[“opster”, “ops”, “so” “cool”,”””😎”””,”awesome”,”””👍””””]
German stop words filter
We can change the stop words for a language of our choice. For example, create a new index same as my_index_with_stopwords index except change the stop words from _english_ to _german_:
PUT my_index_with_stopwords_german
{
"settings": {
"analysis": {
"analyzer": {
"standard_with_stopwords_german":{
"type":"standard",
"stopwords":"_german_"
}
}
}
}
}We can test the text using the aforementioned standard_with_stopwords_german analyzer:
GET my_index_with_stopwords_german/_analyze
{
"text": ["Opster ist genial"],
"analyzer": "standard_with_stopwords_german"
}The output will remove the ist (ist is a common stop word equal to “is” in English) and produce only two tokens: “Opster”,”genial” (= awesome).
File-based stop words
In the previous examples, we provided a clue to the analyzer as to which stop words it should use, English or German, etc., by mentioning the off-the-shelf stop words filter. We can also take this a bit further by providing the stop words via an explicit file (rather than relying on the in-built stop words).
Let’s say we don’t want users to input swear words in our application. We can create a file with all the blacklisted swear words and add the path of the file as the parameter to the standard analyzer. The file must be present relative to the config folder of Elastisearch’s home. The following listing creates the index with an analyzer that accepts a stop word file:
PUT index_with_swear_stopwords
{
"settings": {
"analysis": {
"analyzer": {
"swearwords_analyzer":{
"type":"standard",
"stopwords_path":"swearwords.txt"
}
}
}
}
}We create an index with stopwords_path pointing to a file swearwords.txt. This file is expected to be located in a directory inside the Elasticsearch’s config folder. The file consists of a blacklisted swear words:
- file:swearwords.txt
- damn
- bugger
- bloody hell
- what the hell
- sucks
Once the index is ready with the support to accept stop words from a file, we are ready to put the analyzer with the custom-defined swear words to use:
POST index_with_swear_stopwords/_analyze
{
"text": ["Damn, that sucks!"],
"analyzer": "swearwords_analyzer"
}This code should stop the first and last words going through the indexing process because those two words were in our swear words blacklist.
So far we’ve worked with the standard analyzer in depth. The rest of the built-in analyzers follow a similar pattern. Elasticsearch provides much flexibility when it comes to analyzers: if off-the-shelf analyzers won’t cut it for you, you can create your own custom analyzers. These custom analyzers can be a mix-and-match of existing components from a large stash of Elasticsearch’s component library.
Custom analyzers
Creating a custom analyzer isn’t as hard as it sounds: it’s just creating and setting a “custom” type analyzer during the index creation process in settings configuration. As a norm, we can create a custom analyzer with any number of filters (both character and token) but only one tokenizer.
For example, the code below creates a custom analyzer with one html_strip character filter, one uppercase token filter and it uses off-the-shelf standard tokenizer:
PUT my_index_with_custom_analyzer
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer":{
"type":"custom",
"char_filter":["html_strip"],
"tokenizer":"standard",
"filter":["uppercase"]
}
}
}
}
}The my_custom_analyzer’s definition is set with type being custom, followed by the required components that make up the analyzer. Once we create the index, we can test the analyzer before we wish to put the index into action. The following code snippet provides the test script:
POST my_index_with_custom_analyzer/_analyze
{
"text": "<H1>opster ops is AwEsOmE</H1>",
"analyzer": "my_custom_analyzer"
}This program produces four tokens: [“OPSTER”,”OPS”,”IS”,”AWESOME”], indicating that our html_strip filter removed the H1 HTML tags before letting the standard tokenizer split the field into four tokens based on a whitespace delimiter. Finally, the tokens were uppercased as they passed through the uppercase token filter.
Advanced customization
While default configurations of the analyzer components work most of the time, sometimes we may need to create analyzers with non-default configurations of the components that make up the analyzer. Say we want to use a mapping character filter that would map characters like & to and < and > to less than and greater than, respectively, and so on.
Let’s suppose our requirement is to develop a custom analyzer that parses text for english alphabets to produce an expanded word – for example: a for apple, b for bat etc. In addition to expanding these alphabets to the words, we also wish to produce edge n-grams.
Let’s first write the code for our custom analyzer with advanced configuration. We will discuss the various components after that. The following listing demonstrates the code to create an index with analysis settings.
PUT index_with_alpabet_words_custom_analyzer
{
"settings": {
"analysis": {
"analyzer": {
"alphabet_word_custom_analyzer":{
"type":"custom",
"char_filter":["alphabet_word_mapper"],
"tokenizer":"standard",
"filter":["lowercase", "edge_ngrammer"]
}
},
"char_filter": {
"alphabet_word_mapper":{
"type":"mapping",
"mappings":[
"a => apple",
"b => ball",
"c => cat"
]
}
},
"filter": {
"edge_ngrammer":{
"type":"edge_ngram",
"min_gram":1,
"max_gram":5
}
}
}
}
}The code in the listing is a bit of a handful, however, understanding it is simple and easy. In the first part, where we define a custom analyzer, we provide a list of filters (both character and token filters if needed) and a tokenizer. You can imagine this as an entry point to the analyzer’s definition.
The second part of the code then defines the filters that were referenced earlier. For example, the alphabet_word_mapper, which is defined under a new char_filter section, uses the mapping type as the filter’s type with a set of mappings. In the mappings, we expand and map each of the letters: a -> apple, b -> bat and so on.
The same goes for the filter block, which defines the edge_ngrammer filter. The edge_ngram filter outputs the edge_ngrams from the tokens. So, for example, given “a” as the input, the character filter (alphabet_word_mapper) will map it to “apple” as per the filter settings. This is then passed through the standard tokenizer and finally ending up with the token filter: edge_ngrammer. The edge_ngrammer’s job is to provide edge_ngrams of the tokens, so in this case, it spits out: a, ap, app, appl, apple.
We can execute the test and try it out:
POST index_with_alpabet_words_custom_analyzer/_analyze
{
"text": "a",
"analyzer": "alphabet_word_custom_analyzer"
}This outputs the edge_ngram’s of apple (a, ap, app, appl, apple).
Summary
- The text analysis is the process of analyzing the text fields using either built-in or custom analyzers. The non-text fields are not analyzed.
- The analyzer is made of character filters, a tokenizer and token filters. Every analyzer must have one and only one tokenizer while character and token filters are optional and can be more than one.
- The standard analyzer is the default analyzer. It has no character filter, a standard tokenizer, and two token filters (lowercase and stop); the stop filter is off by default.
- Character filters help strip unwanted characters from an input field. There are three character filters off the shelf: html_strip, mapping and pattern_replace filters.
- Tokenizers act on the fields that were processed by character filters or on raw fields. Elasticsearch provides a handful of out-of-the-box tokenizers.
- The token filters work on the tokens that are emitted by the tokenizer.
- If the built-in analyzers doesn’t suit our needs, we can customize to create a new analyzer by picking up existing tokenizers with character or token filters.