
Quick links
- Background – what are nodes?
- What are node roles?
- Types of node roles
- How to reduce OpenSearch costs by optimizing your node roles
- Useful links
- Conclusion
Background – what are nodes?
Every OpenSearch instance we run is called a node, and multiple nodes comprise a cluster. Each node in a cluster is aware of all other nodes and forwards the requests accordingly. Clusters can consist of only a single node, though this isn’t recommended for production. In this article, we will review the different types of node roles and how to configure these roles in OpenSearch to enable efficient full text search.
What are OpenSearch node roles?
The node role defines the purpose of the node and its responsibilities. We can configure multiple roles for each node based on the cluster configuration. If we don’t explicitly specify the node’s role, OpenSearch automatically configures all roles to that node. This differs among the different versions of OpenSearch.
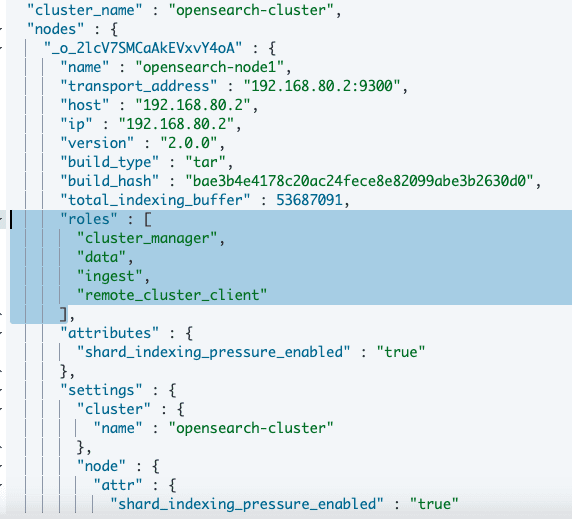
The cluster details of such nodes will appear as:
Types of node roles
- Master (updated to cluster_manager from v1.3 onwards)
- Data
- Search
- Coordinating
- Ingest
- Dynamic
Master node (aka cluster_manager)
The node to which we assign a master role is called a “master” node. The master node manages all cluster operations like creating/deleting an index and it keeps track of all available nodes in the cluster. While creating shards, the master node decides the node upon which each shard should be allocated. This node will not handle any user requests.
When will the master election happen? The election process happens during startup or when the current master node goes down. Any master-eligible node except the “Voting-only” node can become a master node during the master election process.
To set node role, edit the node’s “opensearch.yml” and add the following line:
node.roles: [“master”]
Note: OpenSearch “master” node role was renamed to “cluster_manager” from version 1.3.x and onwards, and “master-eligible” node role was renamed to “cluster_manager-eligible”. You can use the following:
node.roles: [ cluster_manager ]
Data node
The node to which we assign a data role is called a “data” node. A data node holds the indexed data and it takes care of CRUD, search and aggregations (operations related to the data).
Without a data node it is impossible for a cluster to operate. Seeing as all the operations carried out by data nodes are I/O, memory and CPU intensive, it is important to monitor and allocate sufficient data nodes.
There are specialized data roles like data_content, data_hot, data_cold, data_warm and data_frozen which can be used in multi-tier deployment architecture. In general it is NOT necessary to configure all of the specific roles, and you can just use the data role. If you want to configure hot cold architecture, please see this guide.
To set node role, edit the node’s “opensearch.yml” and add the following line:
node.roles: [“data”]
Data hot node
Data hot nodes are part of the hot tier. This role is not necessary unless you want to configure hot-cold architecture.
Hot tier nodes are mainly used to store the most frequently updated and recent data. These types of data nodes should be fast during both search and indexing. Therefore, they require more RAM, CPU and fast storage.
To set this node role, edit the node’s “opensearch.yml” and add the following line:
node.roles: [“data”] node.attr.temp: hot
Note: Instead of assigning it as node.role as in Elasticsearch, it is assigned as an attribute in OpenSearch.
Data warm node
Data warm nodes are part of the warm tier. This role is not necessary unless you want to configure hot-cold architecture.
Warm tier nodes are used for storing time series data that are less frequently queried and rarely updated. Warm nodes will typically have larger storage capacity in relation to their RAM and CPU.
To set this node role, edit the node’s “opensearch.yml” and add the following line:
node.roles: [“data”] node.attr.temp: warm
Note: Instead of assigning it as node.role as in Elasticsearch, it is assigned as an attribute in OpenSearch.
Data cold node
Data cold nodes are part of the cold tier. This role is not necessary unless you want to configure hot-cold architecture.
Time series data that no longer needs to be searched regularly will be moved from the warm tier to the cold tier.
Since search performance is not a priority, these nodes are usually configured to have higher storage capacity for a given RAM and CPU.
To set this node role, edit the node’s “opensearch.yml” and add the following line:
node.roles: [“data”] node.attr.temp: cold
Note: Instead of assigning it as node.role as in Elasticsearch, it is assigned as an attribute in OpenSearch.
In most scenarios it would be enough to use hot-warm only. You should have a good reason to add a cold tier because it also increase the network traffic between nodes and increases the cost of your cluster.
Search node
This role is not necessary unless you want to use the searchable snapshot feature.
Data that is queried rarely and never updated can be moved from hot/warm/cold tier to the search node.
This type of node may reduce storage and operating costs, while still allowing the user to search on searchable snapshot data. It provides access to searchable snapshots, and incorporates techniques like frequently caching used segments and removing the least used data segments in order to access the searchable snapshot index (stored in a remote long-term storage source, for example, Amazon S3 or Google Cloud Storage).
Note: Search nodes contain an index allocated as a snapshot cache. Thus, OpenSearch recommends dedicated nodes with a setup with more compute (CPU and memory) than storage capacity (hard disk) in the official documentation.
To set this node role, edit the node’s “opensearch.yml” and add the following line:
node.roles: [ search ]
Coordinating node
Coordinating-only nodes act as load-balancers. This type of node routes requests to data nodes and handles bulk indexing by distributing the requests.
These types of nodes are used in larger clusters. By getting the cluster state from all the nodes, the coordinating-only node will route requests accordingly.
In small clusters, it is usually not necessary to use a coordinating node, since the same role will be handled by data nodes, and the greater complexity is not justified on a small cluster.
To make a node “coordinating only” node, add the following configuration to the “opensearch.yml” file:
node.roles: []
Ingest node
If there is any pre-processing needed in the indexing using ingest pipelines, ingest nodes can be configured separately to handle it.
Allocating separate nodes to do pre-processing will help to reduce the required resources for all nodes performing this operation.
To make a node an “ingest” node, add the following configuration to the “opensearch.yml” file:
node.roles: [“ingest”]
Dynamic node
Dynamic node is available Opensearch v1.3.x and onwards. It corresponds to the Machine Learning node in Elasticsearch. Delegates a specific node for custom work, such as machine learning (ML) tasks, preventing the consumption of resources from data nodes and therefore not affecting any OpenSearch functionality.
To configure a dynamic (machine learning) node, add the following configuration to the “opensearch.yml” file:
node.roles: [“dynamic”]
How to reduce your OpenSearch costs by optimizing your node roles
Watch the video below to learn how to save money on your deployment by optimizing your node roles.

Useful links
For a full discussion on hot-cold architecture in OpenSearch, please see: https://opster.com/guides/opensearch/opensearch-data-architecture/setting-up-hot-warm-architecture-for-ism/
Conclusion
It is vital to configure the OpenSearch cluster and nodes as per the requirements to build a high-performance and fault-tolerant search application. With this article, we hope you got a clear idea on nodes and roles of each node type, to enable you to configure your cluster accordingly and build an effective search application.