
High Cluster Pending Tasks Event in AutoOps
Background
One of Opster’s customers was dealing with frequent red status troubles in Elasticsearch. Once they connected their cluster to AutoOps, the issue began to become clear. Of the many events detected automatically by AutoOps, one was the “high cluster pending task” event. Together with Opster’s experts, the team began to investigate.
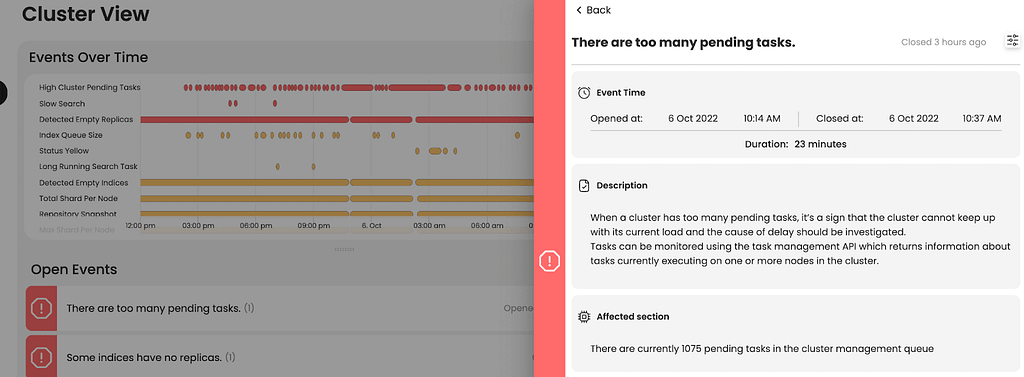
The problem detected
AutoOps detected that there were more than 1000 pending tasks in the cluster. The team called the `GET _cluster/pending_tasks` API and analyzed the result. After examining the outputs, it appeared that the many pending tasks were being caused by thousands of indices which were included in the ILM policy calling for “action: rollover”, though the indices were not suitable for rollovers. Having so many tasks pending in the cluster created too much pressure, leading the cluster to become unresponsive and the master nodes to constantly time out.
Solution
There were more than 5 thousand indices in the cluster. Some of these indices were indexed as rollover, ie <index>-00001, and some as daily, ie <index>-yyyy-MM-dd. First, the team ran the following command to detect which indices had ILM errors:
`GET _all/_ilm/explain?filter_path=**.step`
Then the team made a list of the index names with a few shell scripts. Now the team had the complete list of indices which needed to be updated, and began the process of changing their ILM policies.
However, when they ran the following command, the cluster timed out again.
`PUT <index>-yyyy-MM-dd/_ilm/remove`
They tried increasing the master_timeout time, but it didn’t solve the issue. The customer, together with Opster’s experts, decided to stop all ILM processes and run the following command:
`POST _ilm/stop`
After a while, master nodes started to return to normal and pending tasks had temporarily disappeared, so they tried the command again.
The `PUT <index>-yyyy-MM-dd/_ilm/remove` command now worked successfully.
Then the team added the newly created ILM, which does not contain “action: rollover”, to the existing index as follows.
``PUT <index>/_settings
{"index.lifecycle.name":"ilm_no_rollover"}```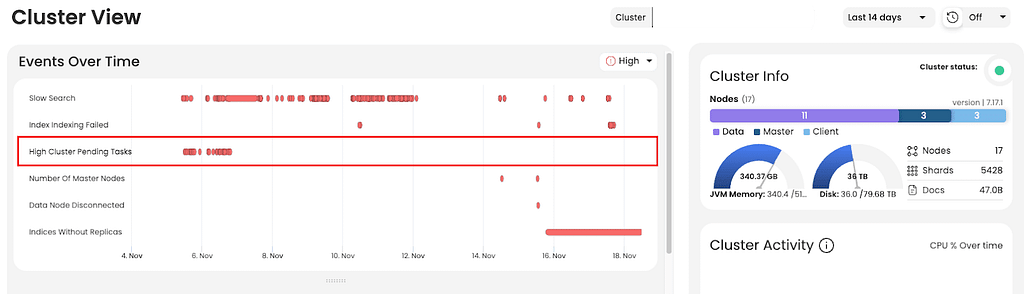
Conclusion
- If the ILM rollover action is in the error state, you cannot insert new ILM policies into the index without deleting the old ILM. You cannot pick up from where it got the error as it won’t accept the new ILM steps.
- The team applied the process to delete the old ILM and add the new ILM to all the indexes detected in a loop. This solved the issue on many pending tasks, the master nodes are stable and the cluster has not restarted since then.
- The AutoOps analysis helped pinpoint the issue related to the masters and their load as a cause of RED status.
- Using AutoOps alerts, the customer was notified proactively before things broke down, and it also allowed the team to monitor how the solution worked.
- Creating and setting ILM policies can have a huge impact on the cluster performance and stability, and should be done with care. Thankfully, the Opster team is here for the rescue when things go wrong 🙂