
Definition
Hotspots is a term referring to a situation in which a cluster with multiple nodes is not balanced – some nodes, for whatever reason, are handling greater load than other nodes. The nodes that are working harder are called hotspots.
Why is it important to take care of hotspots?
Hotspots should not be ignored. When they occur, they form bottlenecks and become the weakest link in the ES/OS process, harming the performance of the entire cluster.
How are hotspots formed?
Hotspots are formed when data is not allocated evenly across the cluster. This can happen for several reasons:
- Data is not allocated evenly across the cluster because sharding hasn’t been configured optimally by the user. An index either has fewer shards than it should or has many more than it should (respectively undersharding and oversharding). For guidelines on how to choose the correct number of shards for your system and configure them correctly, see this guide.
- For large, multi-tenant deployments, data may not be allocated evenly for a different reason. OpenSearch can evenly spread shards and indices across nodes so long as the deployment is relatively small / single tenant. Once the system is more complex, the automatic process performs less well. In general, OpenSearch ensures that every node has the same number of shards (regardless of their sizes!), but because the load on each shard is different, especially in multi-tenancy situations, some nodes can become more loaded than others.
- Scaling up the number of data nodes can cause a hotspot to form. Balancing shards across all nodes is done automatically by OpenSearch, but there are some scenarios in which hotspots form because the rebalancing process takes too long. This can occur when scaling up, as the balancing process will take a long time when nodes have hundreds or thousands of shards. During this time the cluster is still unbalanced, and any new index being created during that time would be allocated to the new nodes which will be carrying the majority of the indexing activity and can become hotspots.
- When a two-node cluster loses one node, replicas automatically get unassigned and all shards present on the remaining node get promoted to primary. When the second node gets back up, it will only host replica shards, hence all the write activity will happen on a single node. The same situation can also arise with bigger HA clusters with forced zone awareness configured.
Impact of hotspots on the cluster
Hotspots negatively impact clusters and performance in multiple ways:
Real-time indexing
Hotspots can cause indexing operations to be delayed and suffer from high latency and lag. This in turn causes fresh data to not be visible in real-time.
Search performance
Hotspots can also cause searches to perform less well. The overloaded node will be lacking sufficient resources to return timely results, and coordinating requests that have at least one shard on this node will be affected, even if most of the shards are not on the hotspot node.
Disconnected nodes
If a certain node is too loaded, it could stop responding to discovery requests, which would then lead to the master disconnecting it from the cluster. Disconnected nodes will then lose their shards which will get reassigned to other live nodes. This can cause cascading effects where the shards are constantly being unassigned/reassigned across nodes in the cluster, causing a lot of traffic (+increase inter-node data transfer costs) and degraded performance.
How to resolve hotspots
To resolve hotspots, the first thing you need is visibility into what is causing the hotspot itself. If you don’t know the source, you won’t be able to address it and get to the correct resolution path.
First, you have to locate which node/s are the bottleneck. Then, you need to take all indices that have shards on these nodes and determine whether:
- The index shards are spread out evenly across the data nodes or not
- Whether the number of primary shards is correct per the indexing load
- Whether the shard sizes are too large
Once you’ve achieved this level of visibility and detected the nodes and unbalanced indices, you need to react with the appropriate actions on these indices. If an index doesn’t have enough primary shards, for instance, then you need to replace the index with an index with more primary shards or just roll over the index after having changed the default number of primary shards in the index template settings. You can also move shards from the loaded nodes to less loaded ones and add or remove replicas as needed.
One way to achieve this level of visibility is to use the Shard View option in AutoOps to automatically detect and resolve hotspots with recommendations tailored to your system. Shard View is made up of heat maps displaying the load of all the index shards on a specific node.
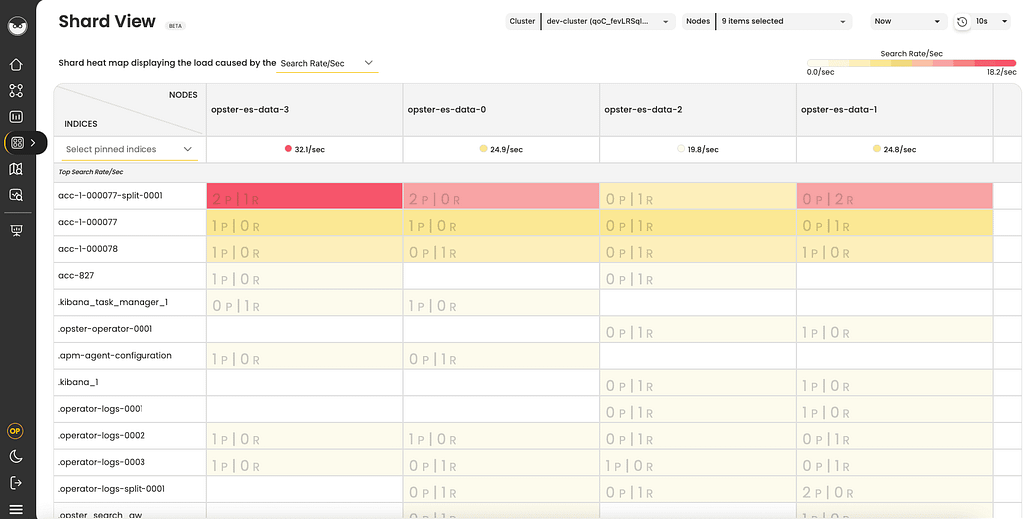
The heat maps can be sorted by different workloads, such as indexing load, search load and storage utilization, affecting the load on the nodes.
A few examples of what you can accomplish using Shard View:
- Detect hotspots and resolve slow indexing
- Improve search performance and balance search across nodes
- Spread storage utilization across nodes and fix watermark issues