What to expect from Opster’s service
With our proactive maintenance, products and professional services, we ensure smooth Elasticsearch operations.

What you can expect from working with Opster

Resolve production crises
First things first, our support engineers help you put out any fires you’re currently dealing with. We stabilize your operation and make sure all of your clusters are running at peak performance.
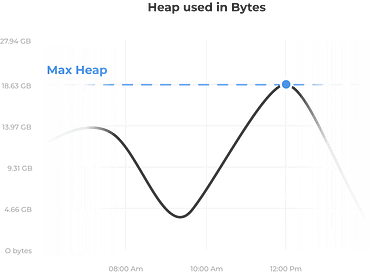
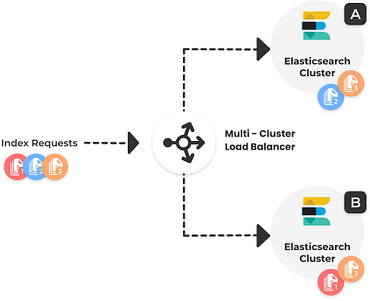
Prevent future incidents
To prevent new crises from occurring, we review and implement best practices for your architecture. We conduct a security review, cover the scale considerations for optimal capacity planning and plan ahead to ensure constant high availability and data recovery.
Optimize performance
Our advanced tools block heavy searches, insure high availability and our Operator performs automatic actions to prevent incidents. These include: balancing shards, splitting indices, resolving Yellow/Red statuses, optimizing templates and more.
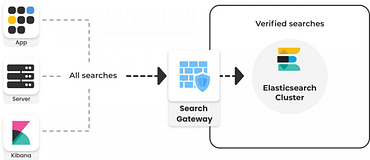
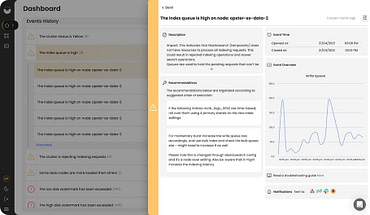
Day-to-day management
Opster's platform and our on-call experts constantly analyze your clusters to pinpoint any issues in advance. We provide you with instructions on how to prevent problems, improve performance and automate operations using the Opster Operator.
Professional services and production support
We conduct periodic sessions to ensure your clusters are operating at peak performance - we review your data modeling, plan for upgrades and apply best practices. In the rare cases that a production incident is not handled automatically, our on-call Elasticsearch expert will be there to assist you to full resolution, RCA and prevention.

Wondering if Opster is right for your company?
If you’re running a non mission-critical installation, we may not be for you. But if you’re running a critical deployment (or planning to), you probably already know that you need a different kind of solution. That's where we come in.
Get pricing for our packages
Contact Us