
Background
In this article we will cover how to avoid critical performance mistakes, why the Elasticsearch default solution doesn’t cut it, and important implementation considerations.
All modern-day websites have autocomplete features (search as you type) on their search bar to improve user experience (no one wants to type entire search terms…). It’s imperative that the autocomplete be faster than the standard search, as the whole point of autocomplete is to start showing the results while the user is typing. If the latency is high, it will lead to a subpar user experience.
Below is an autocomplete search example on the famous question-and-answer site, Quora. This is a good example of autocomplete: when searching for elasticsearch auto, the following posts begin to show in their search bar.
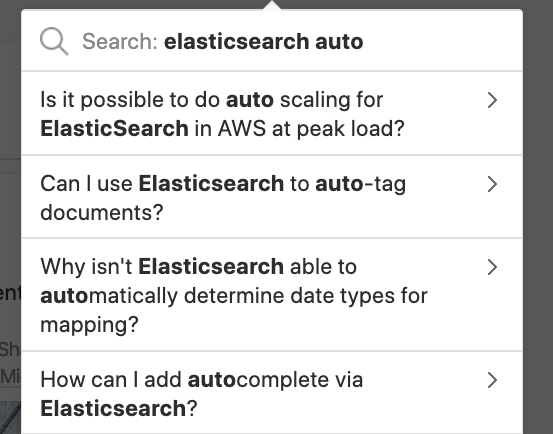
Note that in the search results there are questions relating to the auto-scaling, auto-tag and autocomplete features of Elasticsearch. Users can further type a few more characters to refine the search results.
Various approaches for autocomplete in Elasticsearch / search as you type
There are multiple ways to implement the autocomplete feature which broadly fall into four main categories:
1. Index time
Sometimes the requirements are just prefix completion or infix completion in autocomplete. It’s not uncommon to see autocomplete implementation using the custom-analyzers, which involves indexing the tokens in such a way that it matches the user’s search term.
If we continue with our example, we are looking at documents which consist of “elasticsearch autocomplete”, “elasticsearch auto-tag”, “elasticsearch auto scaling” and “elasticsearch automatically”. The default analyzer won’t generate any partial tokens for “autocomplete”, “autoscaling” and “automatically”, and searching “auto” wouldn’t yield any results.
To overcome the above issue, edge ngram or n-gram tokenizer are used to index tokens in Elasticsearch, as explained in the official ES doc and search time analyzer to get the autocomplete results.
The above approach uses Match queries, which are fast as they use a string comparison (which uses hashcode), and there are comparatively less exact tokens in the index.
2. Query time
Autocomplete can be achieved by changing match queries to prefix queries. While match queries work on token (indexed) to token (search query tokens) match, prefix queries (as their name suggests) match all the tokens starting with search tokens, hence the number of documents (results) matched is high.
As explained, prefix query is not an exact token match, rather it’s based on character matches in the string which is very costly and fetches a lot of documents. Elasticsearch internally uses a B+ tree kind of data structure to store its tokens. It’s useful to understand the internals of the data structure used by inverted indices and how different types of queries impact the performance and results.
Elasticsearch also introduced Match boolean prefix query in ES 7.2 version. This is a combination of Match and Prefix queries and has the best of both worlds. It’s especially useful when you have multiple search terms. For example, if you have `foo bar baz`, then instead of running a prefix search on all the search terms (costly and produces fewer results), this query would prefix search only on the last term and match previous terms in any order. Doing this improves the speed and relevance of the search results.
3. Completion suggester
This is useful if you are providing suggestions for search terms like on e-commerce and hotel search websites. The search bar offers query suggestions, as opposed to the suggestions appearing in the actual search results, and after selecting one of the suggestions provided by completion suggester, it provides the search results.
As mentioned on the official ES doc it is still in development use and doesn’t fetch the search results based on search terms as explained in our example.
Internally it works by indexing the tokens which users want to suggest and not based on existing documents.
Code samples
1. Index time
Index definition:
{
"settings": {
"analysis": {
"filter": {
"autocomplete_filter": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 10
}
},
"analyzer": {
"autocomplete": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"autocomplete_filter"
]
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "autocomplete",
"search_analyzer": "standard" :-> note search_analyzer
}
}
}
}
Search query:
{
"query": {
"match": {
"movie_name": {
"query": "avengers inf"
}
}
}
}2. Query time
Index definition:
{
"mappings": {
"properties": {
"movie_name": {
"type": "text"
}
}
}
}Search query:
{
"query": {
"bool": {
"should": [
{
"match": {
"movie_name": "avengers"
}
},
{
"prefix": {
"movie_name": "inf"
}
}
]
}
}
}4. Search as you type
It is a recently released data type (released in 7.2) intended to facilitate the autocomplete queries without prior knowledge of custom analyzer set up. Elasticsearch internally stores the various tokens (edge n-gram, shingles) of the same text, and therefore can be used for both prefix and infix completion. It can be convenient if not familiar with the advanced features of Elasticsearch, which is the case with the other three approaches. Not much configuration is required to make it work with simple uses cases, and code samples and more details are available on official ES docs.
Performance consideration
Almost all the above approaches work fine on smaller data sets with lighter search loads, but when you have a massive index getting a high number of auto suggest queries, then the SLA and performance of the above queries is essential. The following bullet points should assist you in choosing the approach best suited for your needs:
- Ngram or edge Ngram tokens increase index size significantly, providing the limits of min and max gram according to application and capacity. Planning would save significant trouble in production.
- Allowing empty or few character prefix queries can bring up all the documents in an index and has the potential to bring down an entire cluster. It’s always a better idea to do prefix query only on the term (on few fields) and limit the minimum characters in prefix queries. This can be now solved by using the boolean Match prefix query as explained above.
- ES provided “search as you type” data type tokenizes the input text in various formats. As it is an ES-provided solution which can’t address all use-cases, it’s always a better idea to check all the corner cases required for your business use-case. In addition, as mentioned it tokenizes fields in multiple formats which can increase the Elasticsearch index store size.
- Completion suggests separately indexing the suggestions and doesn’t address the use-case of fetching the search results.
- Index time approaches are fast as there is less overhead during query time, but they involve more grunt work, like re-indexing, capacity planning and increased disk cost. Query time is easy to implement, but search queries are costly. This is very important to understand as most of the time users need to choose one of them and to understand this trade-off can help with many troubleshooting performance issues.
Miscellaneous
In most of the cases, the ES provided solutions for autocomplete either don’t address business-specific requirements or have performance impacts on large systems, as these are not one-size-fits-all solutions. Most of the time, users have to tweak in order to get the optimized solution (more performant and fault-tolerant) and dealing with Elasticsearch performance issues isn’t trivial. Opster helps to detect them early and provides support and the necessary tools to debug and prevent them effectively.
For further reading, check out Opster’s guide on How to Use Search Slow Logs to learn how to quickly debug slow search issues.