
Overview
There are different methods for calculating the storage size of index fields. Below are explanations of the 3 primary methods:
1. Create dedicated indices
The idea of this approach is to create an index with all fields, as well as specific indices with only the field of interest, with the same mapping and setting configuration as the full index. Using the _cat/indices API, it is then possible to compare the relative size of the indexes and draw some statistical conclusions regarding how much space their respective fields are taking.
Bear in mind, though, that this only provides a rough approximation and that the index size must be substantial (i.e. several hundreds of MB) in order to be meaningful as each index takes some overhead space that would make the comparison of small indices irrelevant.
It is also worth noting that this approach is an option only if the index doesn’t have too many fields to scrutinize. This method will require users to create one index per field under investigation, which is usually okay when you have a few dozen fields, but is less relevant for indices with hundreds or thousands of fields.
Below are all the steps needed to carry out this method.
Creating an index that includes all fields
The all_fields_idx index includes :
- name field of text type (with default standard analyzer)
- name.keyword field of keyword type (i.e using keyword analyzer)
- first_name field of text type with costly n-gram analyzer.
Index mapping for all_fields_idx:
PUT all_fields_idx
{
"settings": {
"analysis": {
"analyzer": {
"ngram_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "ngram",
"min_gram": 1,
"max_gram": 10,
"token_chars": [
"letter",
"digit"
]
}
}
},
"max_ngram_diff": 25
},
"mappings": {
"properties": {
"first_name": {
"type": "text",
"analyzer": "ngram_analyzer"
}
}
}
}
Documents for all_fields_idx :
You can index the documents in all_fields_idx using bulk API as shown below:
POST all_fields_idx/_bulk
{ "index": {}}
{ "name": "Nelson Mandela","first_name": "Nelson"}
{ "index": {}}
{ "name": "Pope Francis","first_name": "Pope"}
{ "index": {}}
{ "name": "Elon Musk","first_name": "Elon"}
{ "index": {}}
{ "name": "Mahatma Gandhi","first_name": "Mahatma"}
{ "index": {}}
{ "name": "Bill Gates","first_name": "Bill"}
{ "index": {}}
{ "name": "Barack Obama","first_name": "Barack"}
{ "index": {}}
{ "name": "Richard Branson","first_name": "Richard"}
{ "index": {}}
{ "name": "Steve Jobs","first_name": "Steve"}
{ "index": {}}
{ "name": "Mohammad Yunus","first_name": "Mohammad"}
{ "index": {}}
{ "name": "Narendra Modi","first_name": "Narendra"}
{ "index": {}}
{ "name": "Abraham Lincoln","first_name": "Abraham"}
{ "index": {}}
{ "name": "Coco Chanel","first_name": "Coco"}
{ "index": {}}
{ "name": "Anne Frank","first_name": "Anne"}
{ "index": {}}
{ "name": "Albert Einstein","first_name": "Albert"}
{ "index": {}}
{ "name": "Walt Disney","first_name": "Walt"}
{ "index": {}}
{ "name": "Sachin Tendulkar","first_name": "Sachin"}
{ "index": {}}
{ "name": "Michael Jackson","first_name": "Michael"}
{ "index": {}}
{ "name": "Marilyn Monroe","first_name": "Marilyn"}
{ "index": {}}
{ "name": "Kalpana Chawla ","first_name": "Kalpana"}
{ "index": {}}
{ "name": "Rosa Parks","first_name": "Rosa"}Creating an index that includes only first_name field
Now we’ll create an index that includes only the desired field we want to calculate. The first_name_idx index includes:
- first_name field of text type with n-gram analyzer
Index mapping for first_name_idx:
PUT first_name_idx
{
"settings": {
"analysis": {
"analyzer": {
"ngram_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "ngram",
"min_gram": 1,
"max_gram": 10,
"token_chars": [
"letter",
"digit"
]
}
}
},
"max_ngram_diff": 25
},
"mappings": {
"dynamic": "false",
"properties": {
"first_name": {
"type": "text",
"analyzer": "ngram_analyzer"
}
}
}
}Reindex API:
Now, to add the documents in first_name_idx you can use the reindex API to index the documents from all_fields_idx.
POST /_reindex
{
"source": {
"index": "all_fields_idx"
},
"dest": {
"index": "first_name_idx"
}
}Since the first_name field is using n-gram analyzer with min_gram = 1 and max_gram = 10, the tokens generated would include:
A, An, Ann, Anne, n, nn, nne, F, Fr, Fra, Fran, Frank, r, ra, ran, rank,...
You can check the tokens generated using the Analyze API:
GET /_analyze/first_name_idx
{
"analyzer" : "ngram_analyzer",
"text" : "Anne Frank"
}Creating an index that includes only name field
The name_idx index includes:
- Name field of text type with standard analyzer (which is the default analyzer for text type field if no analyzer is explicitly defined).
Index Mapping for name_idx:
PUT name_idx
{
"mappings": {
"dynamic": "false",
"properties": {
"name": {
"type": "text"
}
}
}
}Reindex API:
Now, to add the documents in name_idx you can use the reindex API to index the documents from all_fields_idx.
POST /_reindex
{
"source": {
"index": "all_fields_idx"
},
"dest": {
"index": "name_idx"
}
}Creating an index that includes only name field of keyword type
The name_keyword_idx index includes:
- Name field of keyword type which uses keyword analyzer
Index mapping for name_keyword_idx:
PUT name_keyword_idx
{
"mappings": {
"dynamic": "false",
"properties": {
"name": {
"type": "keyword"
}
}
}
}Reindex API:
To add the documents in name_keyword_idx you can now use the reindex API to index the documents from all_fields_idx.
POST /_reindex
{
"source": {
"index": "all_fields_idx"
},
"dest": {
"index": "name_keyword_idx"
}
}Comparing the storage size between the indices
You can check the primary storage size of each index using the CAT indices API:
http://localhost:9200/_cat/indices/*_idx?v
Which will give you information of all the above 4 indices in your cluster, to give you an idea of the approximate size of each field:

Notes:
- all_fields_idx index, which contains all the fields, has a primary storage size of 8.6kb. Compared to the other 3 indices, this index has the most storage size because it contains all text, keyword, and n-gram analyzer fields.
- first_name_idx index’s primary storage capacity is 7.1kb since it contains the first_name field, a text field that uses n-gram analysis. As was already indicated, numerous tokens (ranging from 1 to 10) will be generated for each text. Thus, this would logically require more space.
- name_idx and name_keyword_idx have a primary storage size of about 5kb. This is due to the fact that the name field utilizes a text field with a standard analyzer, which simply breaks on whitespace. In contrast, the keyword name field uses a keyword analyzer, which prevents text from breaking and allows it to be treated as a single token.
- In short, ultimately index size depends on the number and types of tokens generated, which again depends on the configured analyzer. The example above used only 20 documents in order to show the impact of tokens and analyzers. The impact would be greater on a bigger dataset. Using the analyze API and reindexing process described, you can measure the size of a few problematic text fields in your index.
2. Using the Luke tool
Luke is a Lucene utility tool that allows one to browse, search and maintain indices and documents.
In order to install and run it, you need to download the Luke release that is compatible with the Lucene version of your OpenSearch install.
You can either download either lucene-8.7.0.tgz or lucene-8.7.0.zip depending on which platform you are on. After downloading and extracting the tarball or ZIP file, you can run the following commands which will launch the Luke tool:
$ cd ./lucene-8.7.0/luke
$ ./luke.sh
Once the GUI shows up, you’ll be prompted to pick the folder containing the index to investigate:
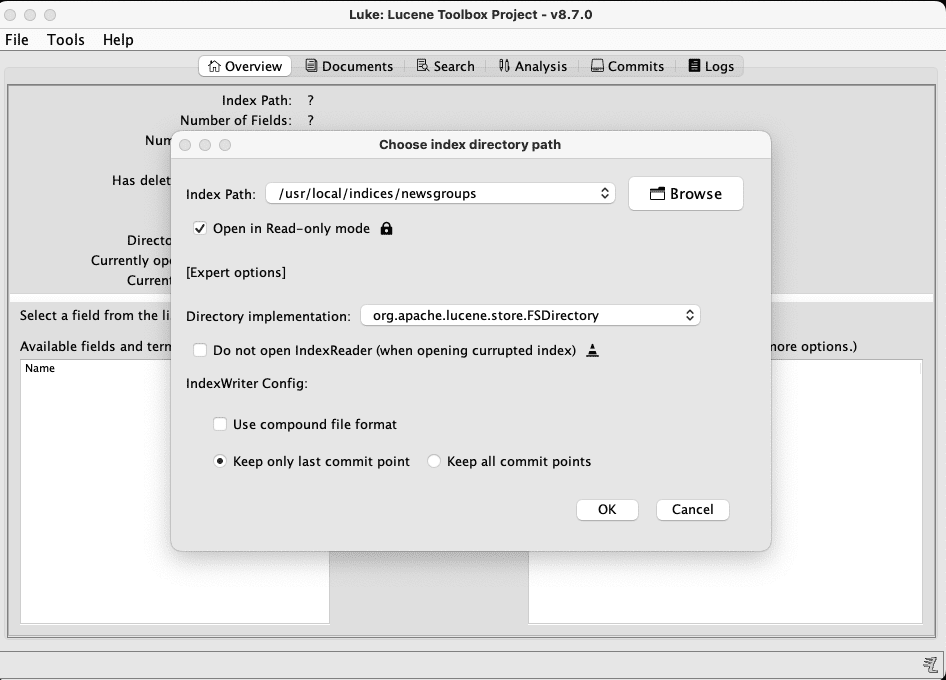
Once the index is opened, you can do a lot of things. But for the task at hand, you can simply head over to the Overview tab and inspect all the fields of the chosen index. By default, all fields are sorted by term count, cBy clicking on each field in the left pane, you can see the top ranking terms for that fields in the right pane. It’s pretty much the same information that can be retrieved from the term vectors API, but in a form that is easier to digest. Using the relative percentages and the overall index size, you can deduce how much space each field is taking.
In the right pane, it is also interesting to see the frequency of the top ranking terms.
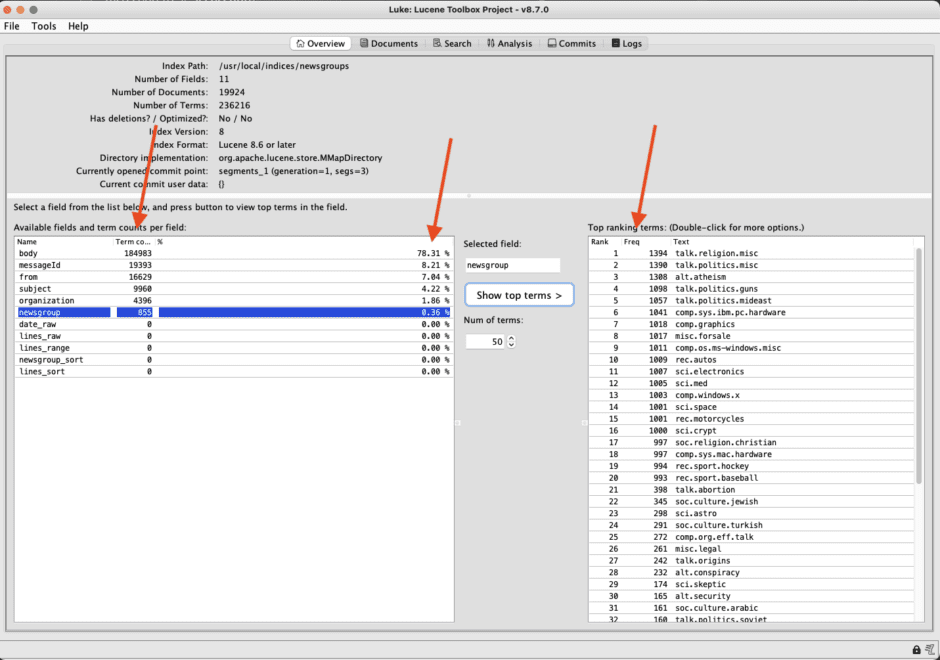
Notes and good things to know
The two following things are also worth noting:
- This only gives an indication of approximately how much disk space the field values are taking, but we cannot draw any conclusions about the requirements for the corresponding heap size, because that depends on many other factors (analyzers, completion, norms, etc).
- It goes without saying but do not run this in production and make sure to have a backup of your index handy, just in case something goes wrong.
In any case, Luke should provide some interesting insights for the task at hand, i.e. estimating the field storage size requirements.